This page is addressed to go-developers who would like to get a better understanding of how godi performs it's tasks.
Build Instructions
Building godi can be accomplished as usual. However, in order to build the web-frontend, additional dependencies are required.
To accomplish this, change directory into the web/client directory and follow the installation instructions of the README.md found therein.
Once the installation is complete, you can build godi by providing the "web" build tag, such as in
# from the project root
## Update the clientdata.go file to allow building and local debugging
go-bindata -debug -ignore "[/\\\\]\\..*" -nomemcopy=true -o $bindatadest -pkg=server -prefix=web/client/app web/client/app/...
# from the project root
go build -tags web
Package Overview
godi is a small package with just a few parts, as illustrated by the following diagram.
As you can see, the api, utility and io packages are rather standalone and don't require much to work, whereas the highest level packge dealing with the command-line interface, cli, directly and indirectly uses all packages underneath.
For further reading, you can have a look at the respective godoc site.
Architecture
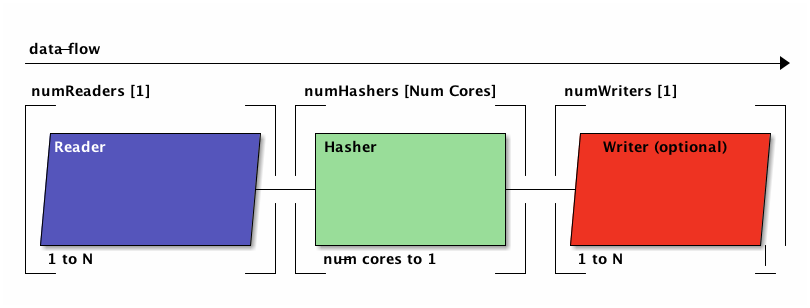
What's far more interesting than the package structure is the architecture. At the heart, godi sets up a pipeline between three components
- generator (producer)
- gather (worker)
- aggregator (fan-in/reducer)
Let's have a look at a more complex commandline to see which components will be set up:
godi seal /media/A/A /media/A/B /media/B
As there are two volumes, each being it's own device, there will be two generators. From /Volume/A we will read two distinct directories, which will be handled by only one generator.
Each generator reads file stats on a respective tree and transmits them to the connected gather node, which will do the hard thinking and produce hashes accordingly.
The information produced by the gather nodes is fed to a single aggregator, which acts like a fan-in gateway. It processes the gather results, and may pass them on unchanged or changed, it may also generate its own results.
All aggregator results are then passed to the one who initially requested the work for digestion, which would be to log it in case of the command-line application.
About Parallelism
godi sets up a highly parallel pipeline, which starts working in the moment the machine is started. There is no caching or pre-computation.
Let's have a look at a more complex command-line and see what happens internally:
godi -spid 2 sealed-copy -spod 2 /media/A /media/B -- /mnt/D /mnt/E
- 2 generators feed file information into
- 2*2 gatherers
- input
- 2 gatherers read from /media/A
- 2 gatherers read from /media/B
- 4 read parallel reads
- processing
- Each read operation yields a buffer with data (input buffer). While it's used, the reader has to wait.
- The buffer is handed concurrently to
- SHA1 Hasher
- MD5 Hasher
- Writer to /media/A (at most 2 writes at the same time, to 4 different open files)
- Writer to /media/B (as above, but only for files on /media/B)
- When all of the above are done processing, the buffer is reused for reading the next piece of the input, until the input file was read completely.
- Produce a gather result which is handed to the aggregator
- Obtain the next file information and repeat
- input
- 1 aggregator
- collects all results it receives from generator and gather nodes, process them, and pass them on as final output.
- serialization
- 2 open gobz files, which are passed the file information as they reach the aggregator. They are serialized into the file right away.
- finalization
- When there are no more gather results to process, serialization of gather results finishes.
If values for -spid and -spod (*streams-per-input|output-device) would be 1, there would just we two gathers, which write at most 1 files in parallel per output device, with 2 files opened per output device at a time.
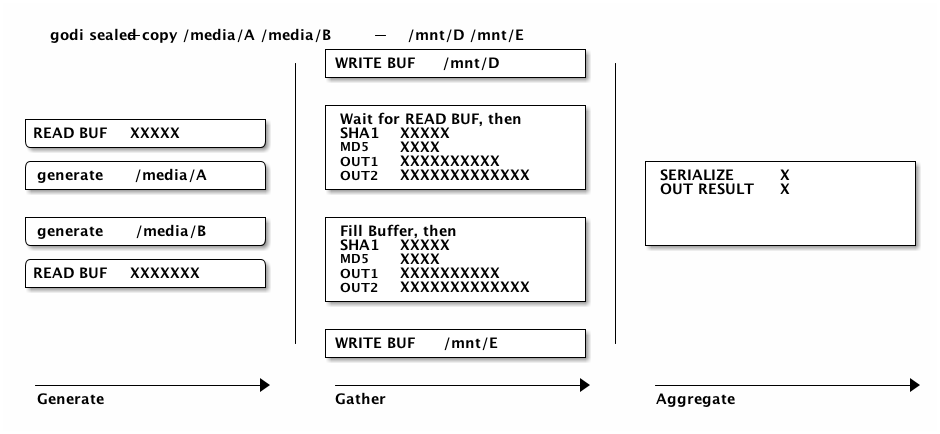
The following diagram attempts to visualize the text above, but with -spid and -spod at 1 to reduce clutter. The big vertical lines can be seen as unix pipes. Thus, in a pipeline like a|b|c, the nodes a, b, and c are running concurrently.
Each node that parallelizes tasks internally shows each task as lane indicates by XXXX. Each lane represents the work done on a single buffer, whereas the longest lane dictates to wall clock time taken. Thus, the slowest tasks determine how fast the operation finishes.
Parallel IO
The image above may only provide an approximation of what really happens regarding the input and output of device data. It tries to indicate that there are in fact Nodes which are to read and write data and deal with gating requests to assure there are never more parallel reads or writes than configured.
This may mean that gather nodes have to wait for IO, as writes in particular may be blocking.
The types behind it are called ReadChannelController and WriteChannelController. When reading, it will always read a whole file sequentially and pass the result to a single gather node.
When writing, it will write individual buffers to (possible) multiple files at the same time, buffer by buffer. Even though pseudo-random writes to multiple open files in parallel might not be optimal, it's something we require as we don't do any caching ourselves. Additionally, device caches usually handle that kind of load well and serialize writes automatically.
Communication and Error Handling
It's quite easy to have everything run in parallel without dealing with anything. Nonetheless, it's very important to react properly to error occurring anywhere in the machine.
godi will react to and handle to any error it sees and judges the error's impact to decide if it can recover. If not, it is possible for gather and aggregator to communicate to the generator* to stop working, for example.
Additionally, there is a shared done channel which is used to signal an interrupt request by the user or some other entity, which has a similar effect as an error.
As the pipeline is dependent on the generator nodes as well as on the device reader, these are the only ones which shut down. This is all that's needed to stop the machine, as gather and aggregate are depending on their input entirely.
This also means that no error or shutdown request will fall under the table.
The current implementation provides a highly responsive program, which will always produce a deterministic result, on error as well as on cancel request, and respond to these without noticeable delay.